トレーニング/テストスクリプトとは別に、 tools/ ディレクトリ以下に多くの便利なツールを提供しています。
ログ分析¶
tools/analysis_tools/analyze_logs.py は、トレーニングログファイルから損失/mAP曲線をプロットします。依存関係をインストールするには、最初に pip install seaborn を実行してください。
python tools/analysis_tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--eval-interval ${EVALUATION_INTERVAL}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
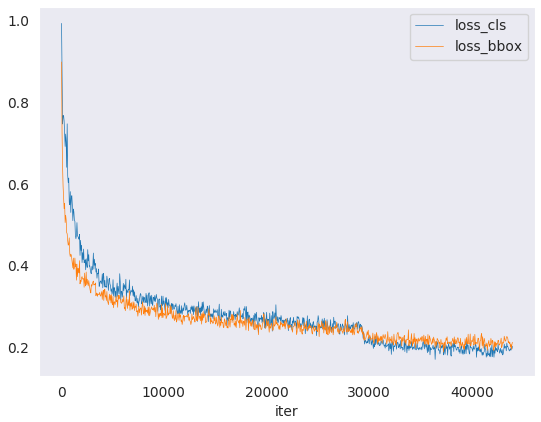
例
ある実行の分類損失をプロットします。
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
ある実行の分類と回帰の損失をプロットし、図をPDFに保存します。
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
同じ図で2つの実行のbbox mAPを比較します。
python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2
平均トレーニング速度を計算します。
python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
出力は次のようになります。
-----Analyze train time of work_dirs/some_exp/20190611_192040.log.json----- slowest epoch 11, average time is 1.2024 fastest epoch 1, average time is 1.1909 time std over epochs is 0.0028 average iter time: 1.1959 s/iter
結果分析¶
tools/analysis_tools/analyze_results.py は、単一画像のmAPを計算し、予測結果に基づいてスコアが最も高い画像と最も低い画像のtopkを保存または表示します。
使用方法
python tools/analysis_tools/analyze_results.py \
${CONFIG} \
${PREDICTION_PATH} \
${SHOW_DIR} \
[--show] \
[--wait-time ${WAIT_TIME}] \
[--topk ${TOPK}] \
[--show-score-thr ${SHOW_SCORE_THR}] \
[--cfg-options ${CFG_OPTIONS}]
すべての引数の説明
config: モデル設定ファイルのパス。prediction_path:tools/test.pyからのpickle形式の出力結果ファイルshow_dir: 描画されたGT画像と検出画像が保存されるディレクトリ--show: 描画された画像を表示するかどうかを決定します。指定しない場合、Falseに設定されます--wait-time: 表示の間隔(秒)、0はブロック--topk: ソート後に最も高いtopkスコアと最も低いtopkスコアを持つ保存された画像の数。指定しない場合、20に設定されます。--show-score-thr: スコアのしきい値を表示します。指定しない場合、0に設定されます。--cfg-options: 指定した場合、キーと値のペアのオプションcfgが設定ファイルにマージされます
例:
tools/test.py からpickle形式の結果ファイルをパス './result.pkl' に取得したとします。
Faster R-CNNをテストし、結果を可視化し、画像をディレクトリ
results/に保存します
python tools/analysis_tools/analyze_results.py \
configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
result.pkl \
results \
--show
Faster R-CNNをテストし、topkを50に指定し、画像をディレクトリ
results/に保存します
python tools/analysis_tools/analyze_results.py \
configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
result.pkl \
results \
--topk 50
低スコアの予測結果を除外したい場合は、
show-score-thrパラメータを指定できます
python tools/analysis_tools/analyze_results.py \
configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
result.pkl \
results \
--show-score-thr 0.3
複数のモデルからの結果の融合¶
tools/analysis_tools/fusion_results.py は、異なるオブジェクト検出モデルからのWeighted Boxes Fusion(WBF)を使用して予測を融合できます。(現在、coco形式のみをサポートしています)
使用方法
python tools/analysis_tools/fuse_results.py \
${PRED_RESULTS} \
[--annotation ${ANNOTATION}] \
[--weights ${WEIGHTS}] \
[--fusion-iou-thr ${FUSION_IOU_THR}] \
[--skip-box-thr ${SKIP_BOX_THR}] \
[--conf-type ${CONF_TYPE}] \
[--eval-single ${EVAL_SINGLE}] \
[--save-fusion-results ${SAVE_FUSION_RESULTS}] \
[--out-dir ${OUT_DIR}]
すべての引数の説明
pred-results: 異なるモデルからの検出結果のパス。(現在、coco形式のみをサポートしています)--annotation: 正解データのパス。--weights: 各モデルの重みのリスト。デフォルト:None、これは各モデルの重み == 1 を意味します。--fusion-iou-thr: ボックスが一一致とみなされるためのIoU値。デフォルト:0.55。--skip-box-thr: WBFアルゴリズムで除外する必要がある信頼度のしきい値。信頼度がこの値未満のbboxは除外されます。デフォルト:0。--conf-type: 重み付きボックスで信頼度を計算する方法。avg: 平均値、デフォルト。max: 最大値。box_and_model_avg: ボックスとモデルごとのハイブリッド加重平均。absent_model_aware_avg: 存在しないモデルを考慮した加重平均。
--eval-single: すべての単一モデルを評価するかどうか。デフォルト:False。--save-fusion-results: 融合結果を保存するかどうか。デフォルト:False。--out-dir: 融合結果のパス。
**例**: tools/test.py を介して対応するモデルから3つの結果ファイルを取得したとします。それらのパスはそれぞれ'./faster-rcnn_r50-caffe_fpn_1x_coco.json'、'./retinanet_r50-caffe_fpn_1x_coco.json'、'./cascade-rcnn_r50-caffe_fpn_1x_coco.json'です。正解ファイルのパスは'./annotation.json'です。
3つのモデルからの予測の融合とその有効性の評価
python tools/analysis_tools/fuse_results.py \
./faster-rcnn_r50-caffe_fpn_1x_coco.json \
./retinanet_r50-caffe_fpn_1x_coco.json \
./cascade-rcnn_r50-caffe_fpn_1x_coco.json \
--annotation ./annotation.json \
--weights 1 2 3 \
各単一モデルと融合結果を同時に評価する
python tools/analysis_tools/fuse_results.py \
./faster-rcnn_r50-caffe_fpn_1x_coco.json \
./retinanet_r50-caffe_fpn_1x_coco.json \
./cascade-rcnn_r50-caffe_fpn_1x_coco.json \
--annotation ./annotation.json \
--weights 1 2 3 \
--eval-single
3つのモデルからの予測結果の融合と保存
python tools/analysis_tools/fuse_results.py \
./faster-rcnn_r50-caffe_fpn_1x_coco.json \
./retinanet_r50-caffe_fpn_1x_coco.json \
./cascade-rcnn_r50-caffe_fpn_1x_coco.json \
--annotation ./annotation.json \
--weights 1 2 3 \
--save-fusion-results \
--out-dir outputs/fusion
可視化¶
データセットの可視化¶
tools/analysis_tools/browse_dataset.py は、ユーザーが検出データセット(画像とバウンディングボックスの注釈の両方)を視覚的に参照したり、画像を指定されたディレクトリに保存したりするのに役立ちます。
python tools/analysis_tools/browse_dataset.py ${CONFIG} [-h] [--skip-type ${SKIP_TYPE[SKIP_TYPE...]}] [--output-dir ${OUTPUT_DIR}] [--not-show] [--show-interval ${SHOW_INTERVAL}]
モデルの可視化¶
最初に、こちらで説明されているように、モデルをONNXに変換します。現在、RetinaNetのみがサポートされており、他のモデルのサポートは今後のバージョンで提供される予定です。変換されたモデルは、Netronのようなツールで可視化できます。
予測の可視化¶
検出結果を可視化するための軽量なGUIが必要な場合は、DetVisGUIプロジェクトを参照してください。
エラー分析¶
tools/analysis_tools/coco_error_analysis.py は、COCOの結果をカテゴリ別および様々な基準で分析します。また、有用な情報を提供するためのプロットを作成することもできます。
python tools/analysis_tools/coco_error_analysis.py ${RESULT} ${OUT_DIR} [-h] [--ann ${ANN}] [--types ${TYPES[TYPES...]}]
例
パス「checkpoint」にMask R-CNNチェックポイントファイルがあるとします。他のチェックポイントについては、モデル動物園を参照してください。
結果のbboxを保存するために、test_evaluatorを以下のように変更できます。
「configs/base/datasets」にあるどのデータセットが現在の設定に対応しているかを確認します。
データセット設定のコメントにある元のtest_evaluatorとtest_dataloaderを、test_evaluatorとtest_dataloaderに置き換えます。
以下のコマンドを使用して、結果のbboxとセグメンテーションjsonファイルを取得します。
python tools/test.py \
configs/mask_rcnn/mask-rcnn_r50_fpn_1x_coco.py \
checkpoint/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
カテゴリごとにCOCO bboxエラー結果を取得し、分析結果画像をディレクトリに保存します(設定では、デフォルトのディレクトリは「./work_dirs/coco_instance/test」です)
python tools/analysis_tools/coco_error_analysis.py \
results.bbox.json \
results \
--ann=data/coco/annotations/instances_val2017.json \
カテゴリごとにCOCOセグメンテーションエラー結果を取得し、分析結果画像をディレクトリに保存します。
python tools/analysis_tools/coco_error_analysis.py \
results.segm.json \
results \
--ann=data/coco/annotations/instances_val2017.json \
--types='segm'
モデルサービング¶
TorchServeを使用してMMDetectionモデルを提供するには、以下の手順に従います。
1. TorchServeのインストール¶
PyTorchとMMDetectionが正常にインストールされたPython環境がある場合、以下のコマンドを実行してTorchServeとその依存関係をインストールできます。その他のインストールオプションについては、クイックスタートを参照してください。
python -m pip install torchserve torch-model-archiver torch-workflow-archiver nvgpu
注:DockerでTorchServeを使用する場合は、torchserve dockerを参照してください。
2. MMDetectionからTorchServeへのモデルの変換¶
python tools/deployment/mmdet2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
--output-folder ${MODEL_STORE} \
--model-name ${MODEL_NAME}
3. TorchServeの起動¶
torchserve --start --ncs \
--model-store ${MODEL_STORE} \
--models ${MODEL_NAME}.mar
4. デプロイメントのテスト¶
curl -O curl -O https://raw.githubusercontent.com/pytorch/serve/master/docs/images/3dogs.jpg
curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg
以下のようなレスポンスが得られるはずです。
[
{
"class_label": 16,
"class_name": "dog",
"bbox": [
294.63409423828125,
203.99111938476562,
417.048583984375,
281.62744140625
],
"score": 0.9987992644309998
},
{
"class_label": 16,
"class_name": "dog",
"bbox": [
404.26019287109375,
126.0080795288086,
574.5091552734375,
293.6662292480469
],
"score": 0.9979367256164551
},
{
"class_label": 16,
"class_name": "dog",
"bbox": [
197.2144775390625,
93.3067855834961,
307.8505554199219,
276.7560119628906
],
"score": 0.993338406085968
}
]
結果の比較¶
test_torchserver.pyを使用して、TorchServeとPyTorchの結果を比較し、視覚化できます。
python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}] [--score-thr ${SCORE_THR}] [--work-dir ${WORK_DIR}]
例
python tools/deployment/test_torchserver.py \
demo/demo.jpg \
configs/yolo/yolov3_d53_8xb8-320-273e_coco.py \
checkpoint/yolov3_d53_320_273e_coco-421362b6.pth \
yolov3 \
--work-dir ./work-dir
5. TorchServeの停止¶
torchserve --stop
モデルの複雑さ¶
tools/analysis_tools/get_flops.pyは、flops-counter.pytorchから改変されたスクリプトで、指定されたモデルのFLOPsとパラメータを計算します。
python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
以下のような結果が得られます。
==============================
Input shape: (3, 1280, 800)
Flops: 239.32 GFLOPs
Params: 37.74 M
==============================
**注**: このツールはまだ実験段階であり、数値が絶対に正しいことを保証するものではありません。単純な比較には結果を使用できますが、技術レポートや論文に採用する前に必ず再確認してください。
FLOPsは入力形状に関連しますが、パラメータは関連しません。デフォルトの入力形状は(1, 3, 1280, 800)です。
GNやカスタム演算子など、一部の演算子はFLOPsにカウントされません。詳細は、
mmcv.cnn.get_model_complexity_info()を参照してください。2段階検出器のFLOPsは、提案の数に依存します。
モデル変換¶
MMDetectionモデルからONNXへ¶
モデルをONNX形式に変換するためのスクリプトを提供しています。また、検証のためにPytorchとONNXモデルの出力結果を比較することもできます。詳細はmmdeployを参照してください。
MMDetection 1.xモデルからMMDetection 2.xへ¶
tools/model_converters/upgrade_model_version.pyは、以前のMMDetectionチェックポイントを新しいバージョンにアップグレードします。このスクリプトは、新しいバージョンでは破壊的な変更が導入されているため、動作を保証するものではありません。新しいチェックポイントを直接使用することをお勧めします。
python tools/model_converters/upgrade_model_version.py ${IN_FILE} ${OUT_FILE} [-h] [--num-classes NUM_CLASSES]
RegNetモデルからMMDetectionへ¶
tools/model_converters/regnet2mmdet.pyは、pyclsで事前学習されたRegNetモデルのキーをMMDetectionスタイルに変換します。
python tools/model_converters/regnet2mmdet.py ${SRC} ${DST} [-h]
Detectron ResNetからPytorchへ¶
tools/model_converters/detectron2pytorch.pyは、元のdetectronで事前学習されたResNetモデルのキーをPyTorchスタイルに変換します。
python tools/model_converters/detectron2pytorch.py ${SRC} ${DST} ${DEPTH} [-h]
公開用のモデルの準備¶
tools/model_converters/publish_model.pyは、ユーザーが公開用のモデルを準備するのに役立ちます。
AWSにモデルをアップロードする前に、次のことが必要になる場合があります。
モデルの重みをCPUテンソルに変換する
オプティマイザの状態を削除する
チェックポイントファイルのハッシュを計算し、ハッシュIDをファイル名に追加する。
python tools/model_converters/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
例:
python tools/model_converters/publish_model.py work_dirs/faster_rcnn/latest.pth faster_rcnn_r50_fpn_1x_20190801.pth
最終的な出力ファイル名はfaster_rcnn_r50_fpn_1x_20190801-{ハッシュID}.pthになります。
データセット変換¶
tools/data_converters/には、CityscapesデータセットとPascal VOCデータセットをCOCO形式に変換するためのツールが含まれています。
python tools/dataset_converters/cityscapes.py ${CITYSCAPES_PATH} [-h] [--img-dir ${IMG_DIR}] [--gt-dir ${GT_DIR}] [-o ${OUT_DIR}] [--nproc ${NPROC}]
python tools/dataset_converters/pascal_voc.py ${DEVKIT_PATH} [-h] [-o ${OUT_DIR}]
データセットのダウンロード¶
tools/misc/download_dataset.pyは、COCO、VOC、LVISなどのデータセットのダウンロードをサポートしています。
python tools/misc/download_dataset.py --dataset-name coco2017
python tools/misc/download_dataset.py --dataset-name voc2007
python tools/misc/download_dataset.py --dataset-name lvis
中国のユーザーは、これらのデータセットをOpenDataLabから高速でダウンロードすることもできます。
ベンチマーク¶
堅牢な検出ベンチマーク¶
tools/analysis_tools/test_robustness.pyとtools/analysis_tools/robustness_eval.pyは、ユーザーがモデルの堅牢性を評価するのに役立ちます。中心となるアイデアは、Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Comingから来ています。破損した画像でモデルを評価する方法と、一連の標準モデルの結果については、robustness_benchmarking.mdを参照してください。
FPSベンチマーク¶
tools/analysis_tools/benchmark.pyは、ユーザーがFPSを計算するのに役立ちます。FPS値には、モデルのフォワード処理と後処理が含まれます。より正確な値を得るために、現在、単一GPU分散起動モードのみをサポートしています。
python -m torch.distributed.launch --nproc_per_node=1 --master_port=${PORT} tools/analysis_tools/benchmark.py \
${CONFIG} \
[--checkpoint ${CHECKPOINT}] \
[--repeat-num ${REPEAT_NUM}] \
[--max-iter ${MAX_ITER}] \
[--log-interval ${LOG_INTERVAL}] \
--launcher pytorch
例:Faster R-CNNモデルのチェックポイントをディレクトリcheckpoints/に既にダウンロード済みであるとします。
python -m torch.distributed.launch --nproc_per_node=1 --master_port=29500 tools/analysis_tools/benchmark.py \
configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
--launcher pytorch
その他¶
メトリックの評価¶
tools/analysis_tools/eval_metric.pyは、設定ファイルに従ってpkl結果ファイルの特定のメトリックを評価します。
python tools/analysis_tools/eval_metric.py ${CONFIG} ${PKL_RESULTS} [-h] [--format-only] [--eval ${EVAL[EVAL ...]}]
[--cfg-options ${CFG_OPTIONS [CFG_OPTIONS ...]}]
[--eval-options ${EVAL_OPTIONS [EVAL_OPTIONS ...]}]
設定全体を出力する¶
tools/misc/print_config.pyは、すべてのインポートを展開して、設定全体を逐語的に出力します。
python tools/misc/print_config.py ${CONFIG} [-h] [--options ${OPTIONS [OPTIONS...]}]
ハイパーパラメータの最適化¶
YOLOアンカーの最適化¶
tools/analysis_tools/optimize_anchors.pyは、YOLOアンカーを最適化するための2つの方法を提供します。
1つは、darknetを参照したk-meansアンサークラスターです。
python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm k-means --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
もう1つは、差分進化を使用してアンカーを最適化することです。
python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm differential_evolution --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
例:
python tools/analysis_tools/optimize_anchors.py configs/yolo/yolov3_d53_8xb8-320-273e_coco.py --algorithm differential_evolution --input-shape 608 608 --device cuda --output-dir work_dirs
あなたは得るでしょう
loading annotations into memory...
Done (t=9.70s)
creating index...
index created!
2021-07-19 19:37:20,951 - mmdet - INFO - Collecting bboxes from annotation...
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 117266/117266, 15874.5 task/s, elapsed: 7s, ETA: 0s
2021-07-19 19:37:28,753 - mmdet - INFO - Collected 849902 bboxes.
differential_evolution step 1: f(x)= 0.506055
differential_evolution step 2: f(x)= 0.506055
......
differential_evolution step 489: f(x)= 0.386625
2021-07-19 19:46:40,775 - mmdet - INFO Anchor evolution finish. Average IOU: 0.6133754253387451
2021-07-19 19:46:40,776 - mmdet - INFO Anchor differential evolution result:[[10, 12], [15, 30], [32, 22], [29, 59], [61, 46], [57, 116], [112, 89], [154, 198], [349, 336]]
2021-07-19 19:46:40,798 - mmdet - INFO Result saved in work_dirs/anchor_optimize_result.json
混同行列¶
混同行列は、予測結果のサマリーです。
tools/analysis_tools/confusion_matrix.pyは、予測結果を分析し、混同行列テーブルをプロットできます。
まず、tools/test.pyを実行して、.pkl検出結果を保存します。
次に、実行します
python tools/analysis_tools/confusion_matrix.py ${CONFIG} ${DETECTION_RESULTS} ${SAVE_DIR} --show
そして、あなたは次のような混同行列を得るでしょう

COCO分離&オクルージョンマスクメトリック¶
オクルージョンされたオブジェクトを検出することは、最先端のオブジェクト検出器にとって依然として課題です。論文A Tri-Layer Plugin to Improve Occluded Detectionで提示されたメトリックを実装して、分離されたマスクとオクルージョンされたマスクのリコールを計算しました。
このメトリックを使用するには、2つの方法があります
オフライン評価¶
ダンプされた予測ファイルを使用してメトリックを計算するスクリプトを提供します。
まず、tools/test.pyスクリプトを使用して、検出結果をダンプします
python tools/test.py ${CONFIG} ${MODEL_PATH} --out results.pkl
次に、tools/analysis_tools/coco_occluded_separated_recall.pyスクリプトを実行して、分離されたマスクとオクルージョンされたマスクのリコールを取得します
python tools/analysis_tools/coco_occluded_separated_recall.py results.pkl --out occluded_separated_recall.json
出力は次のようになります
loading annotations into memory...
Done (t=0.51s)
creating index...
index created!
processing detection results...
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 5000/5000, 109.3 task/s, elapsed: 46s, ETA: 0s
computing occluded mask recall...
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 5550/5550, 780.5 task/s, elapsed: 7s, ETA: 0s
COCO occluded mask recall: 58.79%
COCO occluded mask success num: 3263
computing separated mask recall...
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3522/3522, 778.3 task/s, elapsed: 5s, ETA: 0s
COCO separated mask recall: 31.94%
COCO separated mask success num: 1125
+-----------+--------+-------------+
| mask type | recall | num correct |
+-----------+--------+-------------+
| occluded | 58.79% | 3263 |
| separated | 31.94% | 1125 |
+-----------+--------+-------------+
Evaluation results have been saved to occluded_separated_recall.json.
オンライン評価¶
CocoMeticから継承したCocoOccludedSeparatedMetricを実装しています。トレーニング中に分離されたマスクとオクルージョンされたマスクのリコールを評価するには、設定で評価メトリックタイプを'CocoOccludedSeparatedMetric'に置き換えるだけです
val_evaluator = dict(
type='CocoOccludedSeparatedMetric', # modify this
ann_file=data_root + 'annotations/instances_val2017.json',
metric=['bbox', 'segm'],
format_only=False)
test_evaluator = val_evaluator
このメトリックを使用する場合は、論文を引用してください
@article{zhan2022triocc,
title={A Tri-Layer Plugin to Improve Occluded Detection},
author={Zhan, Guanqi and Xie, Weidi and Zisserman, Andrew},
journal={British Machine Vision Conference},
year={2022}
}